
 Factor Analysis of Information Risk (FAIR™) provides a model for understanding, analyzing, and quantifying cyber risk and operational risk in financial terms. Among the various components of the model designed to support risk quantification, FAIR includes a framework for establishing data collection criteria.
Factor Analysis of Information Risk (FAIR™) provides a model for understanding, analyzing, and quantifying cyber risk and operational risk in financial terms. Among the various components of the model designed to support risk quantification, FAIR includes a framework for establishing data collection criteria.
RiskLens has developed a platform purpose-built on FAIR. Data can be centrally collected, stored, and managed within the RiskLens application, and accessed and updated by other applications using the RiskLens APIs.
RiskLens is the leader in software and services for quantitative risk analysis and risk management.
Every organization that starts down the path of risk quantification has asked themselves at one point or another, “Do I have enough data to utilize FAIR?” The truth is, you need less data to do defensible quantitative analysis than you’d think, and you likely have more data available already than you realize. There is no real prerequisite to use FAIR. It’s a journey and an iterative process to provide more and more meaningful results for the business. That said, RiskLens does help you start effectively building a program through the use of Data Helpers.
 Author Adam Lamantia is an Account Executive for RiskLens.
Author Adam Lamantia is an Account Executive for RiskLens.
Data for Cyber Risk Quantification with the RiskLens Platform
Data libraries and Data Helpers supply the frequency and magnitude inputs necessary for an analysis and are built based on industry data. This data is from a variety of sources, including the Verizon DBIR and Advisen Cyber Loss Data to name a few. The RiskLens data science team analyzes tens of thousands of data points from actual breaches and curates the data to ensure its statistical relevance and applicability for a FAIR analysis and use in the RiskLens platform. The data is then further segmented by industry to maximize its relevance for customers. All data sources and assumptions are documented so you can be confident in reliability.
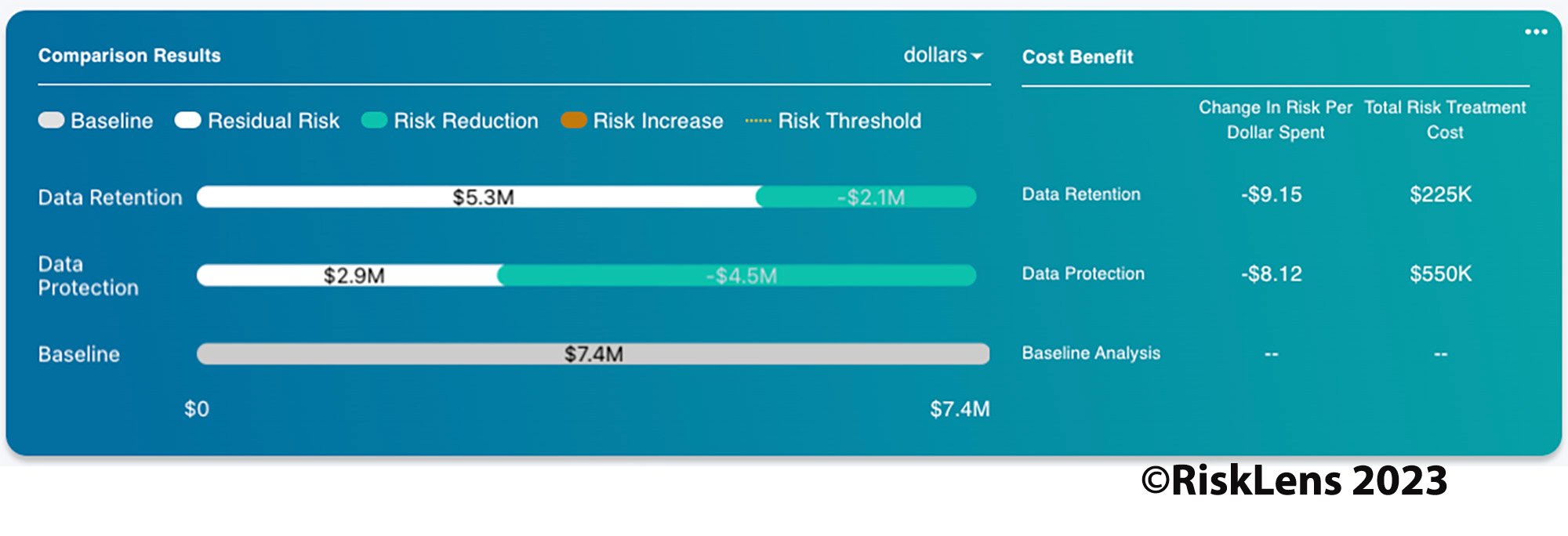 Image: Cost-benefit analysis on the RiskLens quantitative analytics platform
Image: Cost-benefit analysis on the RiskLens quantitative analytics platform
Data Helpers can be used any time throughout the platform, but they don’t just include the industry data prepared by the RiskLens Data Science team. They are also fully customizable and over time will include specific organizational data, to further improve the relevancy of your analysis. During your onboarding with RiskLens, data experts will help you gather and refine as much data as possible to align the Data Helpers with your company’s business model and geographic location.
More on RiskLens Data Science Research: Read Our 2023 Cyber Risk Report
As you gather data points from SMEs for risk analyses, analysts can store that data in the platform for repeated use in answering risk analysis workshop questions. This storing of data enables consistency in data for future analysis work. Things like credit monitoring cost per customer, probability of a ransomware attack, hourly wages for response teams, etc can all be stored in these handy data repositories and then plugged into future analysis. But remember, if you’re ever missing some data, the RiskLens Data Helpers are stocked with industry data can help fill in the gaps.
Benefits of Automating Data Input with Data Helpers
Here are some of the top ways your CRQ program can benefit from Data Helpers:
-
Enable analysis even with gaps in organizational data by utilizing industry benchmark data
-
Significantly reduce the amount of time it takes to complete a risk analysis by focusing on data selection over data collection. This leads to a complete analysis in hours rather than days.
-
Store data for future use in order to enable consistent and efficient risk analysis, eliminating the numerous meetings and discussions to repeatedly track down data internally
-
Provide defensible and reliable results by documenting the rationale and data sources used in analysis
As a Senior Information Security Risk Engineer at a large technology platform put it, “RiskLens allows us to save data from every analysis – credit monitoring or response costs, probability of ransomware attack or credit card leakage. Next thing you know you have 200 risk analyses under your belt and you’re really not doing a lot of new research.” When looking for a FAIR-based CRQ solution, the benefits of Data Helpers cannot be overstated.
